
What Do Value-Added Measures of Teacher Preparation Programs Tell Us?
![]()


Dan Goldhaber
Director
Center for Education
Data & Research
Professor
University of
Washington-Bothell
Dan Goldhaber
Highlights
• Policymakers are increasingly adopting the use of student growth measures to measure the performance of teacher preparation programs.
• Value-added measures of teacher preparation programs may be able to tell us something about the effectiveness of a program’s graduates, but they cannot readily distinguish between the pre-training talents of those who enter a program from the value of the training they receive.
• Research varies on the extent to which prep programs explain meaningful variation in teacher effectiveness. This may be explained by differences in methodologies or by differences in the programs.
• Research is only just beginning to assess the extent to which different features of teacher training, such as student selection and clinical experience, influence teacher effectiveness and career paths.
• We know almost nothing about how teacher preparation programs will respond to new accountability pressures.
• Value-added based assessments of teacher preparation programs may encourage deeper discussions about additional ways to rigorously assess these programs.
Introduction
Teacher training programs are increasingly being held under the microscope. Perhaps the most notable of recent calls to reform was the 2009 declaration by U.S. Education Secretary Arne Duncan that “by almost any standard, many if not most of the nation’s 1,450 schools, colleges, and departments of education are doing a mediocre job of preparing teachers for the realities of the 21st century classroom.”[1] Duncan’s indictment comes despite the fact that these programs require state approval and, often, professional accreditation. The problem is that the scrutiny generally takes the form of input measures, such as minimal requirements for the length of student teaching and assessments of a program’s curriculum. Now the clear shift is toward measuring outcomes.
The federal Race to the Top initiative, for instance, considered whether states had a plan for linking student growth to teachers (and principals) and to link this information to the schools in that state that trained them. The new Council for the Accreditation of Educator Preparation (CAEP) just endorsed the use of student outcome measures to judge preparation programs.[2] And there is a new push to use changes in student test scores—a teachers’ value-added—to assess teacher preparation providers (TPPs). Several states are already doing so or plan to soon.[3]
Much of the existing research on teacher preparation has focused on comparing teachers who enter the profession through different routes—traditional versus alternative certification—but more recently, researchers have turned their attention to assessing individual TPPs.[4] And in doing so, researchers face many of the same statistical challenges that arise when value-added is used to evaluate individual teachers. The measures of effectiveness might be sensitive to the student test that is used, for instance, and statistical models might not fully distinguish a teacher’s contributions to student learning from other factors.[5] Other issues are distinct, such as how to account for the possibility that the effects of teacher training fade the longer a teacher is in the workforce.
Before detailing what we know about value-added assessments of TPPs, it is important to be explicit about what value-added methods can and cannot say about the quality of TPPs. Value-added methods may be able to tell us something about the effectiveness of a program’s graduates, but this information is a function both of graduates’ experiences in a program and of who they were when they entered. The point is worth emphasizing because policy discussions often treat TPP value-added as a reflection of training alone. Yet the students admitted to one program may be very different from those admitted to another. Stanford University’s program, for instance, enrolls students who generally have stronger academic backgrounds than those of Fresno State University. So if a teacher who graduated from Stanford turns out to be more effective than a teacher from Fresno State, we should not necessarily assume that the training at Stanford is better.
Because we cannot disentangle the value of a candidate’s selection to a program from her experience there, we need to think carefully about what we hope to learn from comparing TPPs. Some stakeholders may care about the value of the training itself, while others may care about the combined effects of selection and training. Many also are likely to be interested in outcomes other than those measured by value-added, such as the number of teachers, or types of teachers that graduate from different institutions. They may also want to know how likely it is that a graduate from a certain institution will actually find a job or stay in teaching. I elaborate on these issues below.
What is Known About Value-Added Measures of Teacher Preparation Programs?
There are only a handful of studies that link the effectiveness of teachers, based on value-added, to the program in which they were trained.[6] This body of research assesses the degree to which training programs explain the variation in teacher effectiveness, whether there are specific features of training that appear to be related to effectiveness, and what important statistical issues arise when we try to tie these measures of effectiveness back to a training program.
Empirical research reaches somewhat divergent conclusions about the extent to which training programs explain meaningful variation in teacher effectiveness. A study of teachers in New York City, for instance, concludes that the difference between teachers from programs that graduate teachers of average effectiveness and those whose teachers are the most effective is roughly comparable to the (regression-adjusted) achievement difference between students who are and are not eligible for subsidized lunch.[7] Research on TPPs in Missouri, by contrast, finds only very small—and statistically insignificant—differences among the graduates of different programs.[8] There is also similar work on training programs in other states: Florida,[9] Louisiana,[10] North Carolina,[11] and Washington.[12] The findings from these studies fall somewhere between those of New York City and Missouri in terms of the extent to which the colleges from which teachers graduate provide meaningful information about how effective their program graduates are as teachers.
One explanation for the different findings among states is the extent to which graduates from TPPs—specifically those who actually end up teaching—differ from each other.[13] As noted, regulation of training programs is a state function, and states have different admission requirements. The more that institutions within a state differ in their policies for candidate selection and training, the more likely we are to see differences in the effectiveness of their graduates. There is relatively little quantitative research on the features of TPPs that are associated with student achievement, but what does exist offers suggestive evidence that some features may matter.[14] There is some evidence, for instance, that licensure tests, which are sometimes used to determine admission, are associated with teacher effectiveness.[15]
More recently, some education programs have begun to administer an exit assessment (the “edTPA”) designed to ensure that TPP graduates meet minimum standards. But because the edTPA is new, there is not yet any large-scale quantitative research that links performance on it with eventual teacher effectiveness. There is also some evidence that certain aspects of training are associated with a teacher’s later success (as measured by value-added) in the classroom. For example, the New York City research shows that teachers tend to more effective when their student teaching has been well-supervised and aligned with methods coursework, and when the training program required a capstone project that related their clinical experience to training.[16] Other work finds that trainees who student-teach in higher functioning schools (as measured by low attrition) turn out to be more effective once they enter their own classrooms.[17] These studies are intriguing in that they suggest ways in which teacher training may be improved, but, as discussed below, it is difficult to tell definitively whether it is the training experiences themselves that influence effectiveness.
The differences in findings across states may also relate to the methodologies used to determine teacher-training effects. A number of statistical issues arise when we try to estimate these effects based on student achievement. One issue is that we are less sure, in a statistical sense, about the impacts of graduates from smaller programs than we are from graduates of larger ones. This is because the smaller sample of graduates gives us estimates of their effects that are less precise; it is virtually guaranteed that findings for smaller programs will not be statistically significant.[18] Another issue is the extent to which programs should be judged in a particular year based on graduates from prior years. The effectiveness of teachers in service may not correspond with their effectiveness at the time they were trained, and it is certainly plausible that the impact of training a year after graduation would be different than it is five or 10 years later, when a teacher has acculturated to his particular school or district. Most of the studies cited above handle this issue by including only novice teachers—those with three or fewer years of experience—in their samples (exacerbating the issue of small sample sizes).[19] Another reason states may limit their analysis to recent cohorts is that it is politically impractical to hold programs accountable for the effectiveness of teachers who graduated in the distant past, regardless of the statistical implications.
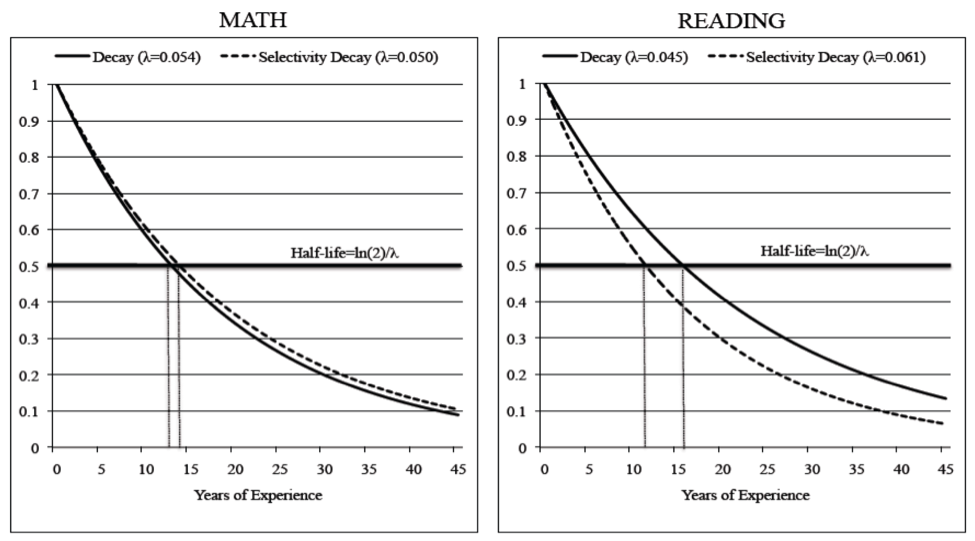
Limiting the sample of teachers used to draw inferences about training programs to novices is not the only option, however. Goldhaber et al., for instance, estimate statistical models that allow training program effects to diminish with the amount of workforce experience that teachers have.[20] These models allow more experienced teachers to contribute toward training program estimates, but they also allow for the possibility that the effect of pre-service training is not constant over a teacher’s career. As illustrated by Figure 1, regardless of whether the statistical model accounts for the selectivity of college (dashed line) or not (solid line), this research finds that the effects of training programs do decay. They estimate that their “half-life”—the point at which half the effect of training can no longer be detected—is about 13–16 years, depending on whether teachers are judged on students’ math or reading tests and on model specification.
A final statistical issue is how a model accounts for factors of school context that might be related both to student achievement and the districts and schools in which TPP graduates are employed. This is a challenging problem; one would not, for instance, want to misattribute district-led induction programs or principal-influenced school environments to TPPs.[21] This issue of context is not fundamentally different from the one that arises when we try to evaluate the effectiveness of individual teachers. We worry, for instance, that between–school comparisons of teachers may conflate the impact of teachers with that of, for instance, principals,[22] but it is particularly problematic in the case of TPPs, when there is little mixing of TPP graduates within a school or school district. This situation may arise when TPPs serve a particular geographic area or espouse a mission aligned to the needs of a particular school district.
What More Needs to be Known on this Issue?
As noted, there are a few studies that connect the features of teacher training to the effectiveness of teachers in the field, but this research is in its infancy. I would argue that we need to learn more about (1) the effectiveness of graduates who typically go on to teach at the high school level; (2) what features of TPPs seem to contribute to the differences we see between in-service graduates of different programs; (3) how TPPs respond to accountability pressures; and (4) how TPP graduates compare in outcomes other than value-added, such as the length of time that they stay in the profession or their willingness to teach in more challenging settings.
First, most of the evidence from the studies cited above is based on teaching at the elementary and middle school levels; we know very little about how graduates from different preparation programs compare at the high school level. And while much of the research and policy discussion treats each TPP as a single institution, the reality is much more complex. Programs produce teachers at both the undergraduate and graduate levels, and they train students to teach different subjects, grades, and specialties. It is conceivable that training effects in one area—such as undergraduate training for elementary teachers—correspond with those in other areas, such as graduate education for secondary teachers. But aside from research that shows a correlation between value-added and training effects across subjects, we do not know how much estimates of training effects from programs within an institution correspond with one another.[23]
Second, we know even less about what goes on inside training programs, the criteria for recruitment and selection of candidates, and the features of training itself. The absence of this research is significant, given the argument that radical improvements in the teacher workforce are likely to be achieved only through a better understanding of the impacts of different kinds of training. There is certainly evidence that these programs differ from one another in their requirements for admission, in the timing and nature of student teaching, and in the courses in pedagogy and academic subjects that they require. But while program features may be assessed during the accreditation and program approval process, there is little data that can readily link these features to the outcomes of graduates who actually become teachers. Teacher prep programs are being judged on some of these criteria (e.g., NCTQ, 2013),[24] but we clearly need more research on the aspects of training that may matter. As I suggest above, it is challenging to disentangle the effects of program selection from training effects; there are certainly experimental designs that could separate the two (e.g., random assignment of prospective teachers to different types of training), but these are likely to be difficult to implement given political or institutional constraints.
Third, we will want to assess how TPPs respond to increased pressure for greater accountability.[25] Post-secondary institutions are notoriously resistant to change from within, but there is evidence that they do respond to outside pressure in the form of public rankings.[26] Rankings for training programs have just been published by the National Council on Teacher Quality (NCTQ) and U.S. News & World Report. Do programs change their candidate selection and training processes because of new accountability pressures? If so, can we see any the impact on the teachers that graduate from them? These are questions that future research could address.[27]
Lastly, I would be remiss in not emphasizing the need to understand more about ways, aside from value-added estimates, that training programs influence teachers. Research, for instance, has just begun to assess the degree to which training programs or their particular features relate to outcomes as fundamental as the probability of a graduate’s getting a teaching job [28] and of staying in the profession.[29] This line of research is important, given that policymakers care not only about the effectiveness of teachers but of their paths in and out of teaching careers.
What Can’t be Resolved by Empirical Evidence on this Issue?
Value-added based evaluation of TPPs can tell us a great deal about the degree to which differences in measureable effects on student test scores may be associated with the program from which teachers graduated. But there are a number of policy issues that empirical evidence will not resolve because they require us to make value judgments. First and foremost is whether or to what extent value-added should be used at all to evaluate TPPs.[30] This is both an empirical and philosophical issue, but it boils down to whether value-added is a true reflection of teacher performance,[31] and whether student test scores should be used as a measure of teacher performance.[32]
Even policymakers who believe that value-added should be used for making inferences about TPPs face several issues that require judgment. The first is what statistical approach to use to estimate TPP effects. For instance, as outlined above, estimating the statistical models requires us to make decisions about whether and how to separate the impact of TPP graduates from school and district environments. And how policymakers handle these statistical issues will influence estimates of how much we can statistically distinguish the value-added based TPP estimates from one program to another (i.e., the standard errors of the estimates and related confidence intervals). And the statistical judgments have potentially important implications for accountability. For instance, we see the 95 percent confidence level used in academic publications as a measure of statistical significance. But, as noted above, this standard likely results in small programs being judged as statistically indistinguishable from the average, an outcome that can create unintended consequences. Take, for instance, the case in which graduates from small TPP “A” are estimated to be far less effective than graduates from large TPP “B,” who are themselves judged to be somewhat less effective than graduates from the average TPP in a state. Graduates from program “A” may not be statistically different from the mean level of teacher effectiveness, at the 95 percent confidence interval, but graduates from program “B” might be. If, as a consequence of meeting this 95 percent confidence threshold, accountability systems single out “B” but not “A,” a dual message is sent. One message might be that a program (“B”) needs improvement. The second message, to program “A,” is “don’t get larger unless you can improve,” and to program “B,” is “unless you can improve, you might want to graduate fewer prospective teachers.” In other words, program “B” can rightly point out that it is being penalized when program “A” is not, precisely because it is a large producer of teachers.
Is this the right set of incentives? Research can show how the statistical approach affects the likelihood that programs are identified for some kind of action, which creates tradeoffs; some programs will be rightly identified while others will not. For more on the implications of such tradeoffs in the case of individual teacher value-added.[33] Research, however, cannot determine what confidence levels ought to be used for taking action, or what actions ought to be taken. Likewise, research can reveal more about whether TPPs with multiple programs graduate teachers of similar effectiveness, but it cannot speak to how, or whether, estimated effects of graduates from different programs within a single TPP should be aggregated to provide a summative measures of TPP performance. Combining different measures may be useful, but the combination itself could mask important information about institutions. Ultimately, whether and how disparate measures of TPPs are combined is inherently a value judgment.
Lastly, it is conceivable that changes to teacher preparation programs—changes that affect the effectiveness of their graduates—could conflict with other objectives. A case in point is the diversity of the teacher workforce, a topic that clearly concerns policymakers and teacher prep programs themselves.[34] It is conceivable that changes to TPP admissions or graduation policies could affect the diversity of students who enter or graduate from TPPs, ultimately affecting the diversity of the teacher workforce.[35] Research could reveal potential tradeoffs inherent with different policy objectives, but not the right balance between them.
Evaluating TPPs: Practicing Implications and Conclusions
It is surprising how little we know about the impact of TPPs on student outcomes given the important role these programs could play in determining who is selected into them and the nature of the training they receive. That’s largely because, in some states, due to new longitudinal data systems, we only now have the capacity to systematically connect teacher trainees from their training programs to the workforce, and then to student outcomes. But we clearly need better data on the admissions and training policies if we are to better understand these links. That said, the existing empirical research does provide some specific guidance for thinking about value-added based TPP accountability. In particular, while it cannot definitively identify the right model to determine TPP effects, it does show how different models change the estimates of these effects and the estimated confidence in them.
To a large extent, how we use estimates of the effectiveness of graduates from TPPs depends on the role played by those who are using them. Individuals considering a training program likely want to know about the quality of training itself.[36] Administrators and professors probably also want information about the value of training to make programmatic improvements. State regulators might want to know more about the connections between TPP features and student outcomes to help shape policy decisions about training programs, such as whether to require a minimum GPA or test scores for admission or whether to mandate the hours of student teaching. But, as stressed above, researchers need more information than is typically available to disentangle the effects of candidate selection from training itself. Given the inherent difficulty of disentangling, one should be cautious about inferring too much about training based on value-added itself.
For other policy or practical purposes, however, it may be sufficient to know only the combined impact of selection and training. Principals or other district officials, for instance, likely wonder whether estimated TPP effects should be considered in hiring, but they may not care much about precisely what features of the training programs lead to differences in teacher effectiveness. Likewise, state regulators are charged with ensuring that prep program graduates meet a minimal quality standard; it is not their job to determine whether that standard is achieved by how the program selects its students or how it teaches them.
The bottom line is that while our knowledge about teacher training is now quite limited, there is a widespread belief that it could be much better. As Arthur Levine, former president of Teachers College, Columbia University, says, “Under the existing system of quality control, too many weak programs have achieved state approval and been granted accreditation.”[37] The hope is that new value-added based assessments of teacher preparation programs will not only provide information about the value of different training approaches, but also will encourage a much-needed and far deeper policy discussion about how to rigorously assess programs for training teachers.
Figure 1: Decay of program effect estimates in math and reading[38]

Recent Comments
No comments to display